Neural Magic Documentation
Neural Magic is a leader in machine learning model optimization and inference acceleration on the hardware of your choice, CPU or GPU. Our software makes your deployments fast and efficient, and your machine learning practice manageable.
Keep tabs on our innovation with resources, examples, news, and more:
- Blog: Neural Magic Leaps Into GPU Acceleration
- New community repo for GPU inferencing:
nm-vllm - Notebook: Quantize LLMs to 4-bit weights, deploy them with Marlin, inside of
nm-vllm!
Example CPU Workflow
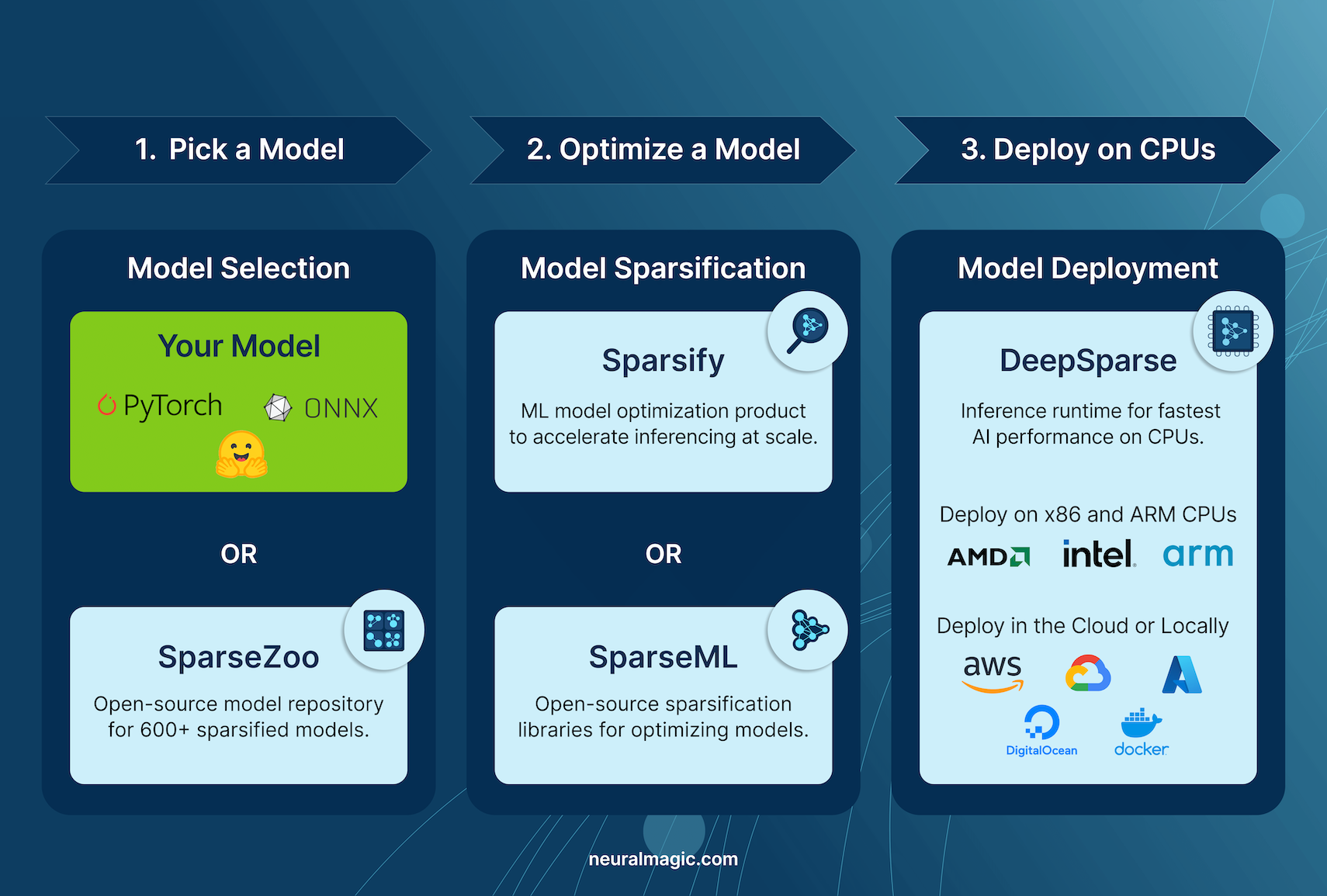
Selecting a Model
Start by choosing the ideal model for your project:
- Neural Magic's Model Repositories: Discover a vast selection of pre-sparsified models across popular use cases in our SparseZoo and Hugging Face repositories. These models are ready for immediate, high-performance deployment.
- Custom Models: Easily integrate your PyTorch or ONNX models into Neural Magic's workflow, applying cutting-edge optimization and deployment techniques tailored to your specific needs.
Optimizing a Model
Achieve unmatched model efficiency with Neural Magic's SparseML. This powerful toolkit leverages state-of-the-art research to streamline your optimization process:
- Advanced Sparsification: Employ sophisticated pruning and quantization strategies to shrink model size and boost inference speed.
- User-Friendly Approach: SparseML is intuitive and accessible, empowering users at all levels to apply advanced optimization techniques effortlessly.
Deploying a Model
Deploy your optimized model with exceptional performance on CPUs using Neural Magic's DeepSparse:
- CPU-Optimized Performance: DeepSparse harnesses the potential of sparsity to deliver GPU-level performance on commodity CPUs, maximizing hardware utilization.
- Seamless Integration: Deploy easily, as DeepSparse smoothly integrates into your existing applications, minimizing development overhead.
Next Steps
Ready to revolutionize your deep learning workflow? Dive into our detailed guides and documentation:
Sections
📄️ Getting Started
Launch your Neural Magic journey with essential setup, installation guides, and foundational concepts.
📄️ Guides
DeepSparse Features and Deployment Options. More to come.
📄️ Products
Gain a comprehensive understanding of Neural Magic's core products (nm-vllm, SparseML, DeepSparse, SparseZoo) and their key features.
📄️ Details
Explore in-depth tutorials and walkthroughs showcasing best practices for model optimization, deployment, and use-case-specific applications.
Tasks
📄️ LLMs - Causal Language Modeling
Harness the power of causal language models for creative text generation tasks, including creative writing, dialogue simulation, and code writing assistance.
📄️ Computer Vision
Optimize and deploy cutting-edge computer vision models for image classification, object detection, and complex image segmentation tasks.
📄️ Natural Language Processing
Optimize and deploy cutting-edge models for natural language processing.
✅ Connect: Join our Slack community to meet like-minded ML practitioners.
✅ Subscribe: Stay informed with our regular email updates.
✅ Contribute: Shape the future of Neural Magic on GitHub (⭐s appreciated!).
✅ Feedback: Help us refine our documentation.