Inference Types With DeepSparse Scheduler
This page explains the various settings for DeepSparse, which enable you to tune the performance to your workload.
Schedulers are special system software, which handle the distribution of work across cores in parallel computation. The goal of a good scheduler is to ensure that, while work is available, cores are not sitting idle. On the contrary, as long as parallel tasks are available, all cores should be kept busy.
Single Stream (Default)
In most use cases, the default scheduler is the preferred choice when running inferences with DeepSparse. The default scheduler is highly optimized for minimum per-request latency, using all of the system's resources provided to it on every request it gets. Often, particularly when working with large batch sizes, the scheduler is able to distribute the workload of a single request across as many cores as it's provided.
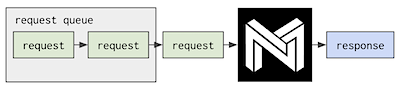
Single-stream scheduling; requests execute serially by default:
Multi-Stream
There are circumstances in which more cores does not imply better performance. If the computation can't be divided up to produce enough parallelism (while maximizing use of the CPU cache), then adding more cores simply adds more compute power with little to apply it to.
An alternative, multi-stream scheduler is provided with the software. In cases where parallelism is low, sending multiple requests simultaneously can more adequately saturate the available cores. In other words, if speedup can't be achieved by adding more cores, then perhaps speedup can be achieved by adding more work.
If increasing core count does not decrease latency, that's a strong indicator that parallelism is low in your particular model/batch-size combination. It may be that total throughput can be increased by making more requests simultaneously. Using the deepsparse.engine.Scheduler API, the multi-stream scheduler can be selected, and requests made by multiple Python threads will be handled concurrently.
Multi-stream scheduling; requests execute in parallel and may better utilize hardware resources:

Whereas the default scheduler will queue up requests made simultaneously and handle them serially, the multi-stream scheduler allows multiple requests to be run in parallel. The num_streams argument to the Engine/Context classes controls how the multi-streams scheduler partitions up the machine. Each stream maps to a contiguous set of hardware threads. By default, only one hyperthread per core is used. There is no sharing amongst the partitions and it is generally good practice to make sure the num_streams value evenly divides into your number of cores. By default num_streams is set to multiplex requests across L3 caches.
Here's an example. Consider a machine with 2 sockets, each with 8 cores. In this case, the multi-stream scheduler will create two streams, one per socket by default. The first stream will contain cores 0-7 and the second stream will contain cores 8-15.
Manually increasing num_streams to 3 will result in the following stream breakdown: threads 0-5 in the first stream, 6-10 in the second, and 11-15 in the last. This is problematic for our 2-socket system. The second stream (threads 6-10) is straddling both sockets, meaning that each request being serviced by that stream is going to incur a performance penalty each time one of its threads makes a remote memory access. The impact of this penalty will depend on the workload, but it will likely be significant.
Manually increasing num_streams to 4 is interesting. Here's the stream breakdown: threads 0-3 in the first stream, 4-7 in the second, 8-11 in the third, and 12-15 in the fourth. Each stream is only making memory accesses that are local to its socket, which is good. However, the first two and last two streams are sharing the same L3 cache, which can result in worse performance due to cache thrashing. Depending on the workload, though, the performance gain from the increased parallelism may negate this penalty.
The most common use cases for the multi-stream scheduler are where parallelism is low with respect to core count, and where requests need to be made asynchronously without time to batch them. Implementing a model server may fit such a scenario and be ideal for using multi-stream scheduling.
Enabling a Scheduler
Depending on your engine execution strategy, enable one of these options by running:
engine = compile_model(model_path, scheduler="single_stream")
or:
engine = compile_model(model_path, scheduler="multi_stream", num_streams=None) # None is the default
or pass in the enum value directly, since "multi_stream" == Scheduler.multi_stream.
By default, the scheduler will map to a single stream.