Why is Weight Sparsity Important for Large Language Models (LLMs)?
Large Language Models (LLMs) have a large size that often poses challenges in terms of computational efficiency and memory usage. Weight sparsity is a technique that can significantly alleviate these issues, enhancing the practicality and scalability of LLMs. Here we outline the key benefits of weight sparsity in LLMs, focusing on three main aspects:
- Decode Performance (how fast we generate new text)
- Prefill Performance (how fast we process existing text)
- Memory Consumption
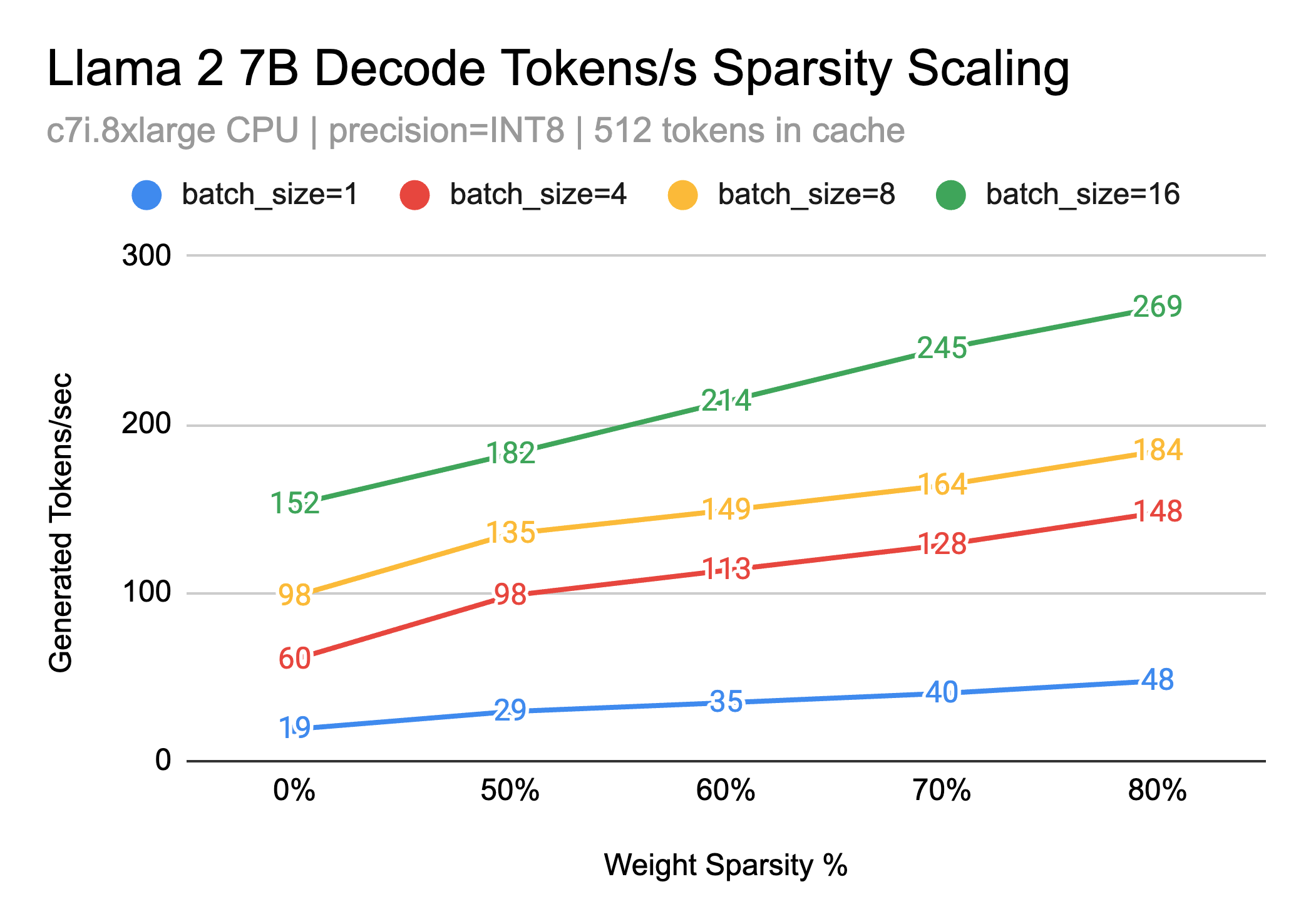
Text Generation Decode Performance
The process of "decoding" tokens is the core loop in text generation that you witness as words come streaming out. For each token produced, all of the LLM's weights must be read. Since these models are usually several gigabytes in size, this can take a lot of time and causes this portion of the pipeline to be highly memory-bound - meaning most of the time is spent waiting for the weights to be read. As a result, compression is king. If the model weights can be made smaller, then we can simply read less memory. This is where sparsity comes in since many weights are zero and can be efficieintly compressed. Compounded with other techniques like quantization, we can start to get really small models and excellent generation latency.
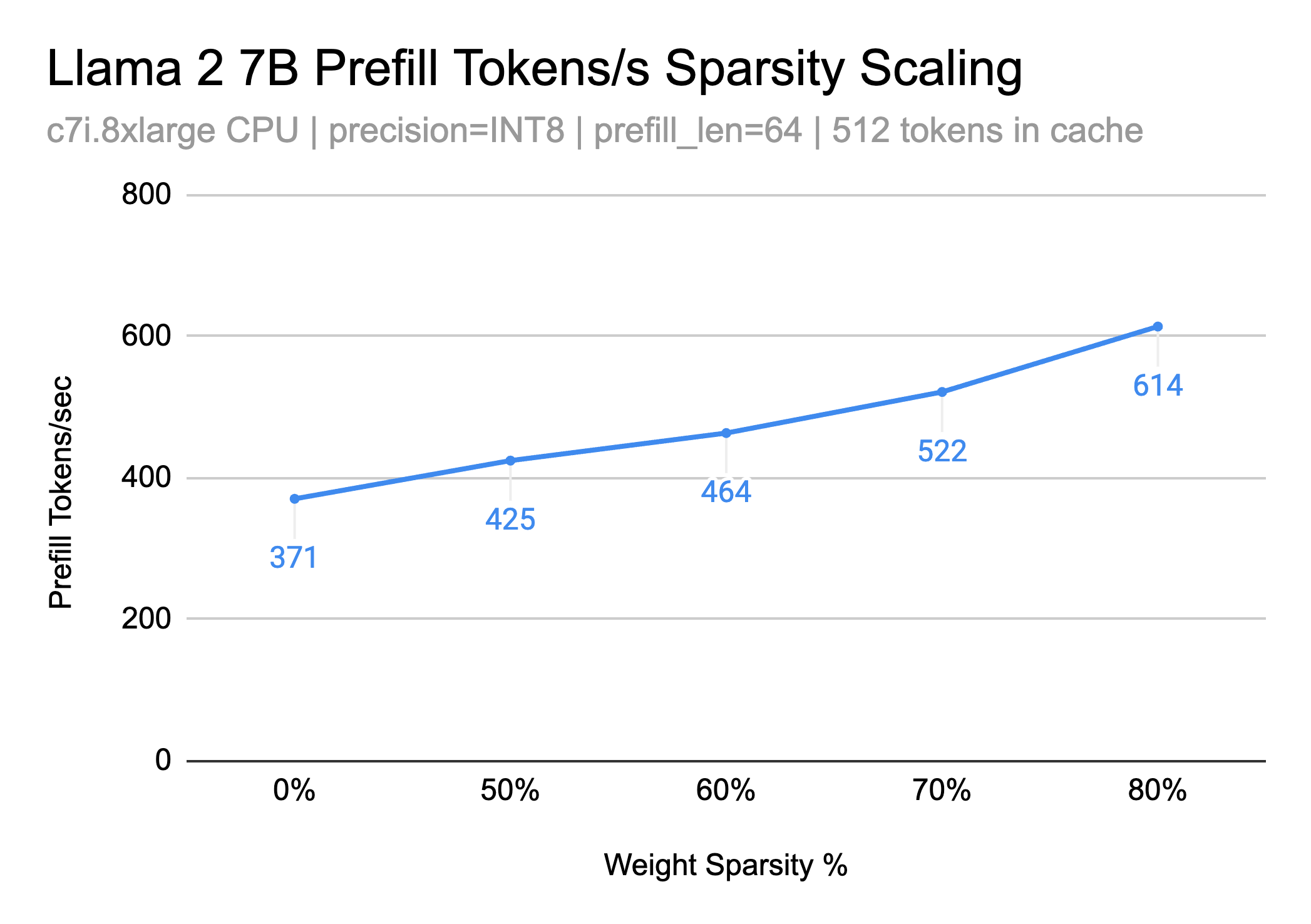
Text Generation Prefill Performance
Prefilling, the process of generating initial context or "priming" the model before actual text generation, is another critical aspect where sparsity plays a vital role. During prefill, the LLM quickly processes a large volume of context data to provide relevant and coherent continuation. Sparse models, due to their reduced number of parameters and effective removal of FLOPs, enable faster processing of this context data, leading to improved prefill performance. This efficiency is particularly beneficial in applications requiring real-time generation or interaction, where latency can significantly impact user experience.
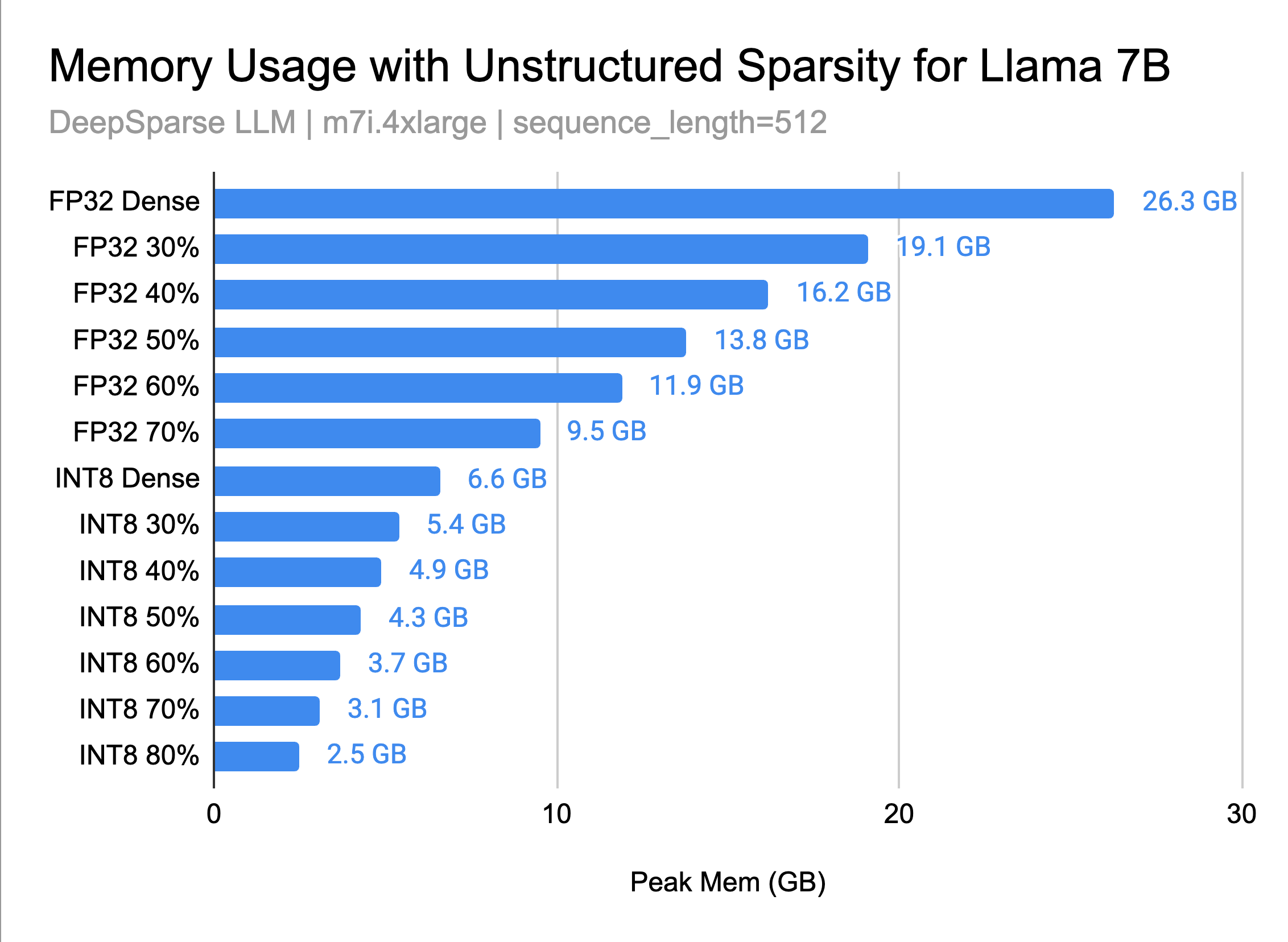
Memory Benefits of Sparsity for LLMs
Sparse models require less memory for storage, as many weights are zero and can be efficiently compressed. This reduction in memory usage is crucial for deploying LLMs on devices with limited memory, such as mobile devices or edge computing platforms. Additionally, the reduced memory footprint enables the parallelization of models on a single machine, allowing for more complex or multiple models to be run simultaneously. This scalability can be particularly beneficial in server environments where space and memory are at a premium. Moreover, the lower memory requirements translate into reduced data transfer costs, especially in cloud-based applications, making LLMs more accessible and cost-effective for a broader range of users and applications.